Most organizations can tell you whether their firewalls are healthy. Fewer can prove every allow rule is inspected, logged, owned, and still required.
The gap between those two things is where audits become painful. Multiple firewall admins, emergency changes at 2am, quarterly reviews that turn into archaeology digs, vendor access rules that were “temporary” in February and are still there in October. Nobody disabled them because nobody noticed they were still there. No alert fires when a rule that was supposed to be temporary quietly becomes permanent.
The Wake-Up Call # On April 9, Gilfoyle (my AI network admin) posted this at midnight:
The cert flap resolved itself within hours. Gilfoyle posted the recovery notice, and ccode closed the escalation. No lasting impact.
The Problem: Nobody’s Watching at 3 AM # My homelab runs 47 guests across 4 Proxmox nodes, with HA pairs for DNS and reverse proxy, a Wazuh XDR deployment, centralized logging in Graylog, and CI/CD automation through Semaphore. It’s a lot of infrastructure for one person to monitor.
I had alerts. Grafana fires when RAM hits 75%. Wazuh flags suspicious file changes. n8n emails me when workflows fail. But alerts are reactive. They tell you something broke. They don’t tell you something is about to break.
TL;DR # My technical blog was squeezing code blocks, tables, and ASCII diagrams into a 650px column designed for novel paragraphs. One CSS line fixed it. The real lesson: defaults optimized for one use case silently degrade another.
The Problem I Didn’t See # I’d been publishing posts for months. Tutorials with wide code blocks. Architecture posts with ASCII flow diagrams. Tables comparing tools and alternatives. Every single one was being crushed into 65ch — roughly 650 pixels of width.
TL;DR # A Python script that identifies every device on your network in PAN-OS traffic logs, without Active Directory. Combines Pi-hole DNS, UniFi Controller, and DHCP leases into one priority merge. 124 devices named on my PA-440.
Before:
1 2 3 192.168.10.128 → 8.8.8.8 user: unknown 192.168.30.240 → 1.1.1.1 user: unknown 172.30.50.77 → 52.26.132.60 user: unknown After:
The Problem: Six Interfaces for One Question # “Is anything broken in my homelab?”
Answering that question used to mean: SSH into Proxmox to check guest status. Curl the Pi-hole API for DNS health. Open Grafana to scan Prometheus alerts. Check Graylog for error spikes. Look at Semaphore for failed automation runs. Glance at Caddy logs for 502s.
The 2 AM Wake-Up Call # I woke up to find my CI/CD platform had been down for 8 hours. Semaphore, the Ansible automation engine that manages my entire homelab, was stuck in a crash loop:
1 2 3 /usr/local/bin/server-wrapper: line 295: syntax error: unexpected "&&" /usr/local/bin/server-wrapper: line 295: syntax error: unexpected "&&" /usr/local/bin/server-wrapper: line 295: syntax error: unexpected "&&" The same error, repeating every few seconds. The container would start, hit the broken entrypoint script, crash, and restart. Endlessly.
The Problem # My Caddy reverse proxy runs as an HA pair – two nodes behind a keepalived VIP. Every service in the homelab gets its traffic through this pair. The setup works great, except for one recurring failure mode: config drift.
The deployment process was manual: edit the Caddy site config in git, SCP it to both nodes, validate, reload. The “both nodes” part is where things break down. It’s easy to deploy to caddy1, test it, see it working, and then forget caddy2 exists. Until keepalived fails over and suddenly half your sites return 502s because the backup node has last week’s config.
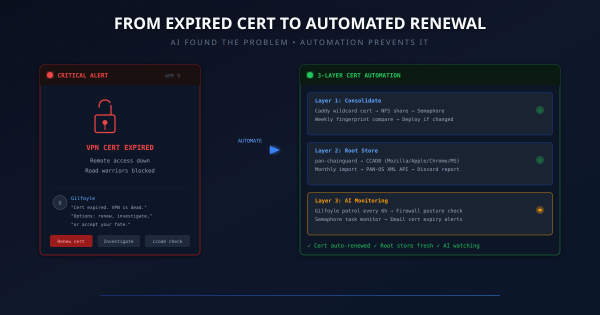
The Problem # My PAN-OS firewall (GlobalProtect VPN portal at vpn.mareoxlan.com) needs a valid TLS certificate. I had a dedicated LXC (30122) running acme.sh with a Cloudflare DNS-01 challenge to issue a wildcard cert, then a PAN-OS deploy hook to push it to the firewall via the XML API. It worked, but it was a single-purpose VM doing the same job my Caddy reverse proxy already does – Caddy auto-renews *.mareoxlan.com via the same Cloudflare DNS-01 mechanism.
Overview # If you’re running SSL decryption on a Palo Alto firewall, you’ve probably hit this: a user reports they can’t access a website, and it turns out the site’s CA certificate isn’t in your firewall’s trusted root store. PAN-OS only updates its built-in root store on major software releases, which means between upgrades your firewall’s trust anchors slowly go stale.